Fine-Tuning vs Prompt Engineering: Which AI Strategy Is Right for You?
1. What Is Prompt Engineering?
2. What Is Fine-Tuning?
3. Fine-Tuning vs Prompt Engineering: A Side-by-Side Comparison
4. Key Differences Between Fine-Tuning and Prompt Engineering
5. When to Use Prompt Engineering
6. When to Use Fine-Tuning
7. What About RAG? Fine-Tuning vs Prompt Engineering vs RAG
8. Can You Combine Fine-Tuning and Prompt Engineering?
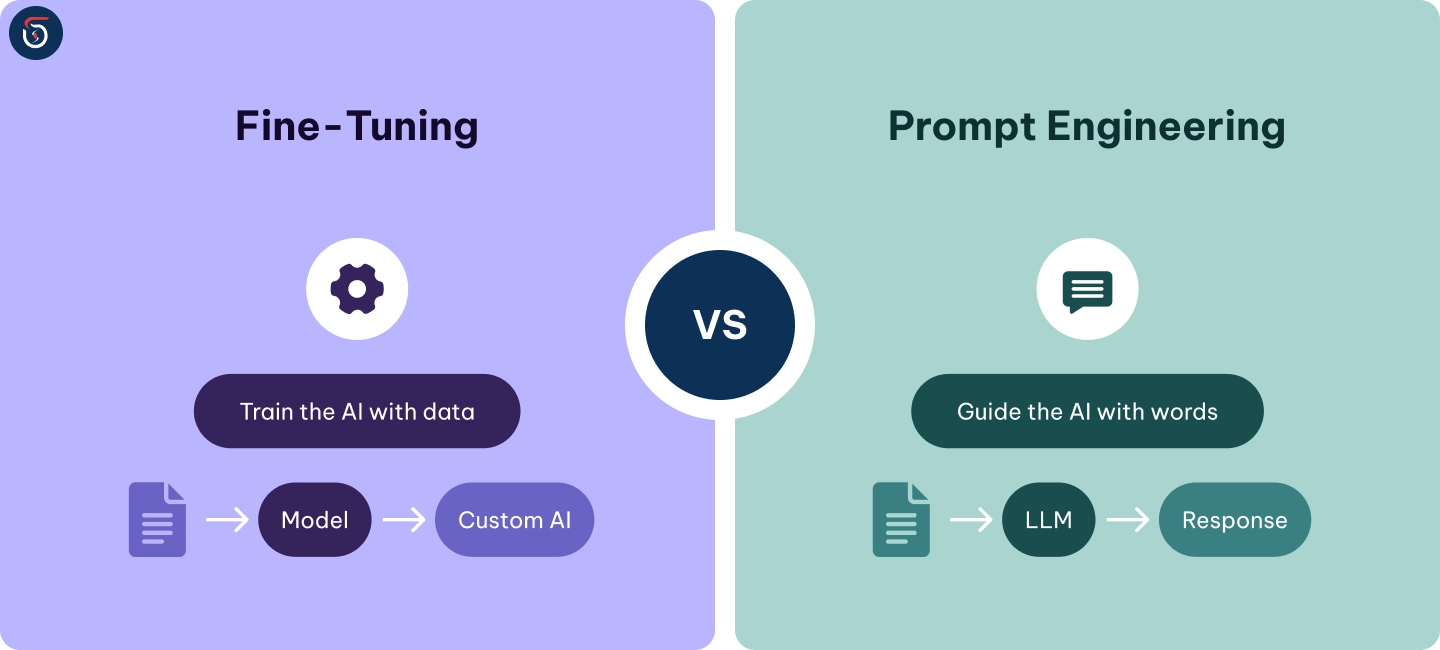
What Is Prompt Engineering?
- ◆Instruction clarity (telling the model exactly what you need)
- ◆Context framing (providing background information)
- ◆Output format (specifying tone, length, structure)
- ◆Few-shot examples (showing the model a few input-output examples before your actual request)
- ◆Chain-of-thought prompting (encouraging the model to follow step-by-step reasoning)
Why Prompt Engineering Matters
What Is Fine-Tuning?
- ◆A legal firm might fine-tune an LLM on thousands of legal briefs so the model generates accurate, jurisdiction-specific language.
- ◆A financial platform might fine-tune a model for fraud detection and risk analysis using fintech software development solutions
- ◆A customer service platform might fine-tune a chatbot on past support conversations to align with its brand voice.
How Was ChatGPT Fine-Tuned?
Fine-Tuning vs Prompt Engineering: A Side-by-Side Comparison

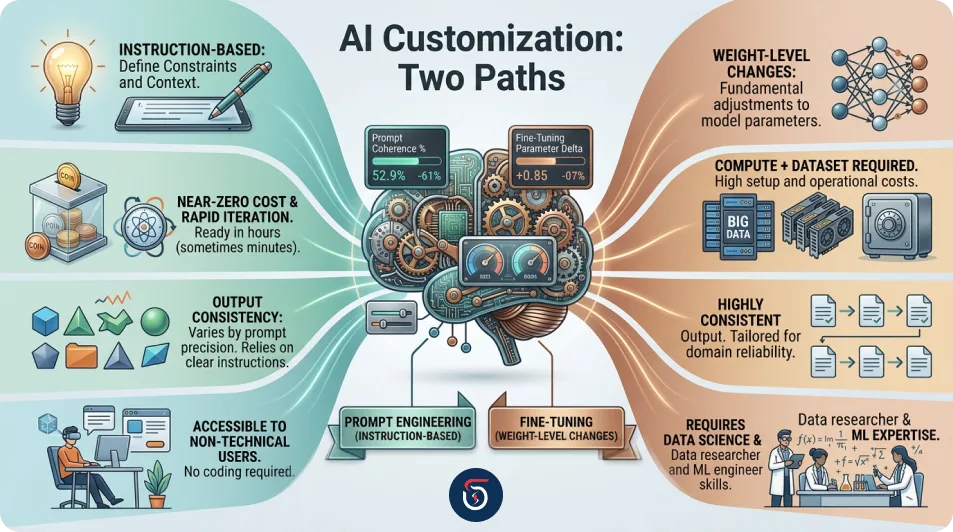
Key Differences Between Fine-Tuning and Prompt Engineering
1. Depth of Customization
2. Cost and Resource Investment
3. Speed of Iteration
4. Consistency of Output
5. Is Fine-Tuning the Same as Prompt Engineering?
When to Use Prompt Engineering
- ◆Speed matters - You need a working prototype in hours, not weeks.
- ◆Budget is limited - No training infrastructure or ML team is available.
- ◆The task is broad - content writing, summarizing, categorizing, answering questions, and translating.
- ◆The model already has domain knowledge - You just need to frame your request effectively.
- ◆Ongoing experimentation is needed - Prompt engineering is ideal for A/B testing different AI behaviors.
When to Use Fine-Tuning
- ◆You need deep specialization - Legal, medical, financial, or technical domains where generic outputs fall short.
- ◆Consistency is mission-critical - Your product must output the same quality and tone at scale.
- ◆You have training data - You've accumulated thousands of labeled examples of high-quality inputs and outputs.
- ◆Latency matters - Fine-tuned models can sometimes be more efficient because complex instructions don't need to be repeated in every prompt.
- ◆You need confidentiality - Your proprietary data can be baked into the model rather than sent as context in every API call.
Is Fine-Tuning Still Relevant in 2026?
What About RAG? Fine-Tuning vs Prompt Engineering vs RAG
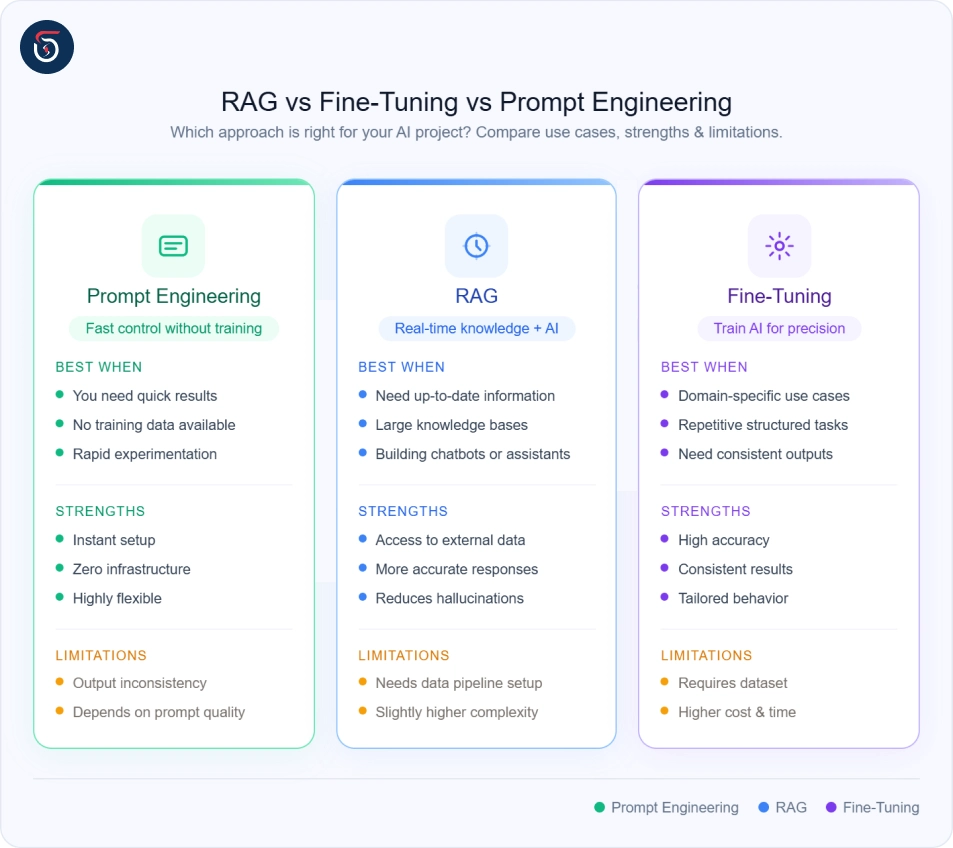
Why RAG Instead of Fine-Tuning?
- ◆Data changes frequently - Product catalogs, news feeds, legal regulations, or internal wikis that update regularly are better served by RAG since fine-tuning would become stale quickly.
- ◆You want explainability - RAG responses can cite their sources, while fine-tuned models can't point to where their knowledge came from.
- ◆You lack training data volume - RAG works with existing documents; fine-tuning requires carefully curated labeled datasets.
- ◆Budget is a concern - Maintaining a RAG pipeline is typically cheaper than running repeated fine-tuning cycles.
Can You Combine Fine-Tuning and Prompt Engineering?
- ◆Fine-tuning = training the model's foundational expertise
- ◆Prompt engineering = directing how that expertise is applied on a per-task basis
If you’re ready to choose the right AI customization approach, explore our AI Services to build scalable, high-performance solutions. Not sure whether prompt engineering, fine-tuning, or RAG fits your needs? Connect with our team and we’ll guide you to the best strategy.
Table of contents
What Is Prompt Engineering?
What Is Fine-Tuning?
Fine-Tuning vs Prompt Engineering: A Side-by-Side Comparison
Key Differences Between Fine-Tuning and Prompt Engineering
When to Use Prompt Engineering
When to Use Fine-Tuning
What About RAG? Fine-Tuning vs Prompt Engineering vs RAG
Can You Combine Fine-Tuning and Prompt Engineering?
Join Our Newsletter
Get the latest tech trends, tutorials and expert analysis delivered straight to your inbox.
Fine-Tuning vs Prompt Engineering FAQs
No. Prompt engineering guides a model's output through carefully crafted inputs without changing the model itself. Fine-tuning retrains the model on new data and updates its internal weights. They are complementary strategies, not the same thing.
Fine-tuning is also referred to as model adaptation, supervised fine-tuning (SFT), transfer learning refinement, or task-specific training in technical and academic contexts.
ChatGPT is a large language model (LLM), which is a specialized category within the broader field of natural language processing (NLP). All LLMs leverage NLP techniques, but not every NLP system qualifies as an LLM.
Prompt engineering shapes outputs through instructions without modifying the model. Fine-tuning updates the model's weights using new training data. RAG retrieves relevant external documents at query time and injects them as context - without changing the model. Each solves a different problem and can be combined for best results.
RAG is preferred when your knowledge base changes frequently, when you want explainable and source-cited responses, or when you lack the labeled dataset volume required for fine-tuning. RAG is also typically more cost-effective especially in industries like **AI in healthcare** where data changes frequently and accuracy is critical.
Absolutely. Many production AI systems combine both: fine-tuning establishes deep domain expertise, while prompt engineering directs that expertise for specific tasks. Pairing both with RAG creates a highly capable, context-aware AI system suited for enterprise use.
Prompt engineering is the best starting point for budget-conscious teams. It requires no model training, minimal infrastructure, and can be iterated quickly. As your product matures and specific pain points emerge, you can evaluate whether fine-tuning or RAG adds meaningful value.